Archive for May 2014
Friday, May 30, 2014
Danny Sullivan:
The form allows an individual or someone representing an individual to put in a request. The form requires submission of a photo ID of the individual the request is for.
[…]
The form then allows people to list one or more URLs they want removed, and they have to provide an explanation about why they want them dropped. In particular, you have to explain why each URL is “irrelevant, outdated, or otherwise inappropriate,” wording that goes back to the original court ruling about why material can be removed.
[…]
Google itself tells Search Engine Land that removals won’t pull a URL out of Google worldwide. Instead, if a removal is approved, the URL will be dropped for searches on the associated name from all the EU-specific versions of Google that the company maintains.
[…]
Google tells us that will show disclosure when URLs are removed under the new Right To Be Forgotten method in a manner similar to above. In other words, while the URL itself is forgotten, the fact that Google was made to forget it will be remembered.
Update (2014-06-05): Brian S. Hall:
To make sense of the right-to-be-forgotten issue—including how it potentially impacts Web users—here’s a look at some questions you may have about the European court’s decision.
Update (2014-11-02): Caitlin Dewey:
But because Lazic lives in Europe, where in May the European Union ruled that individuals have a “right to be forgotten” online, he decided to take the griping one step further: On Oct. 30, he sent The Washington Post a request to remove a 2010 review by Post classical music critic Anne Midgette that – he claims — has marred the first page of his Google results for years.
It’s the first request The Post has received under the E.U. ruling. It’s also a truly fascinating, troubling demonstration of how the ruling could work.
Google Search Web
Dave Wiskus on Vesper 2.0 (App Store):
There’s an argument to be made for making the user enter their password twice, but I don’t buy it. Notes live on the device as well as on the service, so logging out (or not being able to log in) doesn’t carry the penalty of obscuring user data. If you mistyped your password and don’t feel like resetting it when you go to sign in with a second device, you can create a new account with a different email address and lose nothing. Resetting is tied to your email address, so it’s always there as an option.
See also Brent Simmons’ Vesper Sync Diary for the coding side.
Design iOS iOS App Syncing Vesper
Ole Zorn on the new version of Editorial (App Store):
Editorial 1.1 will go live in just a few hours, and I couldn’t be more excited. I’ve been working on this for over nine months, and in a lot of ways, it feels more like a 2.0, or at least 1.5. There’s a new look for iOS 7, an iPhone version, tons of refinements everywhere, and several major new features for building even more powerful workflows.
This post is a rundown of the most important additions; I won’’t mention every single bugfix here; if you want all the details, head over to the release notes.
I haven’t paid much attention to Editorial because until now it has been iPad-only. I’ve just started giving it a try on my iPhone and am blown away by how good it is. So far, at least, I expect that it will become my iPhone text editor of choice. It seems to have all of the features on my list except for full control over colors (just themes), and no special features for rearranging lines or accessing previous file versions on Dropbox. More importantly, it feels very fast and responsive, it has the best multi-file search and in-file searches I’ve seen, and it has a nifty TaskPaper mode.
The one hitch so far is that it only loads one level of files from Dropbox at a time, so a folder isn’t searchable until you’ve viewed its contents in the app. With WriteUp, once I set the desired Dropbox folder, I could immediately search the entire hierarchy. However, the developer assures me that, after you manually view a folder, Editorial will keep syncing it automatically—so I should be good from now on. The reason for this confusing but pragmatic design is that people might want to access files from select subfolders in a large Dropbox folder, without syncing the whole thing.
Dropbox Editorial iOS iOS App Markdown Python TaskPaper Text Editor
Damien Guard:
My love of typography originated in the 80′s with the golden years of 8-bit home computing and their 8×8 pixel mono-spaced fonts on low-resolution displays.
It’s quite easy to find bitmap copies of these fonts and also scalable traced TTF versions but there’s very little discussion about the fonts themselves. Let’s remedy that by firing up some emulators and investigating the glyphs.
Apple II Font History
John Knox:
Keeping the other parameters the same, I set the underperforming ad (the one with a photo of an iPad) to only target iPads. Even one day into the experiment, it seemed like Manton was correct. The CTR for the iPad photo jumped up nicely.
Advertising App Store Business iOS iPad iPhone
Wednesday, May 28, 2014
Drew Crawford links to two great posts about Python 3. Armin Ronacher:
Python 3 takes a very difference stance on Unicode than UNIX does. Python
3 says: everything is Unicode (by default, except in certain situations,
and except if we send you crazy reencoded data, and even then it's
sometimes still unicode, albeit wrong unicode). Filenames are Unicode,
Terminals are Unicode, stdin and out are Unicode, there is so much
Unicode! And because UNIX is not Unicode, Python 3 now has the stance
that it's right and UNIX is wrong, and people should really change the
POSIX specification to add a C.UTF-8 encoding which is Unicode. And
then filenames are Unicode, and terminals are Unicode and never ever will
you see bytes again although obviously everything still is bytes and will
fail.
Nick Coghlan:
The conceptual problem with this [Python 2] model is that it is an appropriate model for
boundary code - the kind of code that handles the transformation between
wire protocols and file formats (which are always a series of bytes), and the
more structured data types actually manipulated by applications (which may
include opaque binary blobs, but are more typically things like text, numbers
and containers).
Actual applications shouldn’t be manipulating values that “might be
text, might be arbitrary binary data”. In particular, manipulating text
values as binary data in multiple different text encodings can easily cause
a problem the Japanese named “mojibake”: binary data that includes text in
multiple encodings, but with no clear structure that defines which parts are
in which encoding.
Unfortunately, Python 2 uses a type with exactly those semantics as its core
string type, permits silent promotion from the “might be binary data” type
to the “is definitely text” type and provides little support for accounting
for encoding differences.
In Cocoa terms, Python 2 uses a mix of NSData (str) and NSString (unicode) to represent strings. As long as you work with NSString, everything is fine. The problem is that some APIs give you NSData when they “should” give you NSString, or they take the NSString that you gave them and at some point convert it to NSData. You can end up in situations where you get back an NSData and don’t know its encoding, or Python tries to concatenate an NSData and an NSString or two NSDatas that implicitly have different encodings (later to be turned back into an NSString). Then you get an exception, and the exception’s stack trace is from when you tried to do something with the “bad” object, not from when the “bad” object was created.
Python 3 is more like Cocoa (or Java). It says that all strings will be NSString (str), which is always Unicode, and everything else is NSData (bytes). You need to take extra care to make sure that you are correctly converting to/from NSString. Otherwise, you can mess up things that might have worked in Python 2 “by accident.” But if you do the work of putting in the proper explicit conversions at the system boundaries, you should end up with a more reliable system where everything inside is clean.
I’m not a Ruby programmer, but I gather that it uses NSData for everything, only each NSData has an associated encoding (which may be “BINARY”). At least you can’t lose track of the encoding. But, like Python 2, every NSData object is potentially “dirty.” If you try to combine two NSDatas that explicitly have different encodings, you get an exception—again, possibly far removed from where the offending object entered your system.
Cocoa Language Design Programming Python Ruby Unicode Unix
Graham Lee notes that Netbot is no longer available from the App Store. It’s removed even for people who have already purchased it. So, unless you save a copy on your Mac, you won’t be able to install it again if you get a new device or restore from an iCloud backup.
App Store App.net iOS iOS App Netbot
Monday, May 26, 2014
Michel Fortin announces Counterparts Lite (Mac App Store):
Counterparts Lite is a full editor for string tables. It lets you add, reorder, and erase entries in the string table. It also permits comments anywhere and has plenty of keyboard shortcuts so you can keep your hands on the keyboard. Counterparts Lite can open binary (compiled) string tables too.
For translators there’s a side-by-side view where you choose a reference file. The edited file will then follow the same structure as the reference. Translating becomes a job of filling the holes. If there is only a few holes they’re easy to find using the filter control at the top.
I wish it supported XLIFF files. This is the first app I’ve seen with an 8-hour trial period.
Counterparts Lite Developer Tool Localization Mac Mac App XLIFF
Christopher Breen:
With Mavericks’ Mail, auto-fill will choose the first alphabetical address, regardless of the order it appears in a contact’s card.
He suggests working around this by creating a group with a single member. This works, but it fills up the groups list (which isn’t hierarchical). Mail’s old way of using the first address wasn’t ideal, either, since Contacts doesn’t let you reorder addresses. I would be nice to have a checkbox for setting the default address.
Apple Mail Contacts E-mail E-mail Client Mac Mac App Mac OS X 10.9 Mavericks
Sunday, May 25, 2014
Google:
Traditionally, we were only looking at the raw textual content that we’d get in the HTTP response body and didn’t really interpret what a typical browser running JavaScript would see. When pages that have valuable content rendered by JavaScript started showing up, we weren’t able to let searchers know about it, which is a sad outcome for both searchers and webmasters.
In order to solve this problem, we decided to try to understand pages by executing JavaScript. It’s hard to do that at the scale of the current web, but we decided that it’s worth it. We have been gradually improving how we do this for some time. In the past few months, our indexing system has been rendering a substantial number of web pages more like an average user’s browser with JavaScript turned on.
Google JavaScript Search Web
Jonathon Mah:
The problem is revealed: there is work to be done after the recursive call: automatic reference counting inserted a release call for the value returned from node.next.
If we were writing this with manual retain/release, one wouldn’t insert any memory management calls into this at all, because -next returns an autoreleased object.
However when this is compiled under ARC, calls to objc_retainAutoreleasedReturnValue and objc_release are inserted to allow for another optimization — having the return value skip the autorelease pool entirely.
Unfortunately in this case, it conflicts with tail call optimization.
[…]
In an ARC environment, tail call optimization (and thus tail recursion) is too fragile. Don’t rely on it.
Automatic Reference Counting (ARC) Objective-C Optimization Programming
Ole Begemann:
When work started on the Mailbox app for Android, the team made the choice to write a large portion of the non-UI code in C++ — rather than rewriting the entire app in Java — with the goal of sharing that common C++ layer between iOS and Android. The iOS app used Core Data at the time, so migrating it off of Core Data to the shared C++ library was also part of the process. C++ seemed like an obvious choice because it is available on every platform and team members preferred the language over Java.
[…]
All UI code uses the native UI APIs on all platforms (Objective-C/UIKit on iOS, Java on Android). Most of the “model layer” code lives in the shared C++ library. Rather than calling it a model layer, Steven likened the design to a client-server architecture where the server (the C++ library) is never offline and has zero latency. Seeing the UI code and the shared library as two separate entities helps design clear interfaces between the two and thus keep the concerns properly separated.
The client-server architecture inside the app also predetermines how data is passed between the UI and the C++ layer. The two layers don’t access the same data objects. They use message passing to send copies of the data from A to B.
Android Android App C++ Programming Language Dropbox iOS iOS App Programming
Danny Sullivan:
At last, it’s time to dig into what happened with MetaFilter. The short story is that I don’t know. MetaFilter doesn’t know. Google knows, and so far, it’s not saying. But we can still do some analysis plus learn how difficult it is sometimes for a publisher to solve a Google penalty, if hit.
Google MetaFilter Web
David Sparks:
Google Documents really is the standard for online document collaboration. I’ve used that tool for years and, while it isn’t all that pretty, it absolutely nails the ability to have multiple people typing on one document at the same time. While Apple is now moving this direction, it hasn’t got there yet. Yesterday I had a small writing project with a Mac-savvy client and I decided to do it collaboratively with him using iCloud Pages. I figured that if the application can support 100 collaborators, it should be pretty solid with just two. It still isn’t.
iCloud iWork Pages.app Web
CrashProbe (via Daniel Jalkut):
CrashProbe is a crash reporting test suite presented by HockeyApp that benchmarks and compares popular iOS and Mac OS X crash reporting services. In our effort to ensure the best possible and most accurate crash reports, we created a set of test cases that we use to verify PLCrashReporter and improve HockeyApp.
Landon Fuller highlights a bug it found in Crashlytics that contradicts its marketing.
Debugging Developer Tool HockeyApp iOS Mac Open Source PLCrashReporter Programming
Informit (via Dr. Drang):
To celebrate the publication of the eBooks of The Art of Computer Programming, (TAOCP), we asked several computer scientists, contemporaries, colleagues, and well-wishers to pose one question each to author Donald E. Knuth. Here are his answers.
Algorithm Book CS Theory Donald Knuth E-books Programming TeX
Thursday, May 22, 2014
OmniFocus 2 (Mac App Store) is now available. In general, I am finding it to be well designed. The menus and options are refined and simplified. It’s a bit less flexible than previous versions, but I think it’s more approachable.
The beta’s problems with low information density remain, though you can somewhat mitigate them by clicking this link to enable the experimental “compact” layout. Even with the single line layout, the window makes less efficient use of space. For example, in OmniFocus 1 there were 219 pixels from the left edge of the window to left edge of my actions. In OmniFocus 2, with the narrowest possible sidebar, it’s 387 pixels. The minimum font size is also larger, so the actions themselves show less text in the same width.
The text itself is now set in ApproximaNova, rather than a font of my choosing. So there’s no way to get high-quality unsmoothed text like I could with Osaka. With font smoothing, the text looks fuzzy on a non-Retina display. They gray note text is especially hard to read.
You can use OmniFocus 1 and 2 simultaneously, since they are sync-compatible. This is interesting for comparing the design, as well as the speed. Some actions, such as flipping views, are faster in 2. Arrow-keying through projects and contexts is much faster in 1. Moving actions up and down has always been slow and still is.
Many of the screenshots show OmniFocus in full screen mode. Indeed, it doesn’t seem to have been designed for small windows. If you have the sidebar or inspector hidden, showing them can grow the window off the right edge of the screen, and hiding them doesn’t always put things back the way they were.
I like the redesigned inspector, but the resizing problems could be avoided if it were available as a popover or floating window. Like the iPhone version, there are now buttons to quickly defer a task for a day, week, or month. I prefer to use a script bound to a keyboard shortcut.
The manual—which is well done—is now available on iBooks. Unfortunately, the Mac version of iBooks doesn’t support scroll wheels and has a distracting animation when paging via the keyboard. The app has a built-in HTML-based help viewer that works better, except that it isn’t searchable. A PDF, with page thumbnails and easy searching, would probably be best.
The app seems to be pretty solid for a new release. The main bugs that I noticed are:
- The “Go to Search Field” menu item and keyboard shortcut don’t always work.
- Services no longer work in the outline when whole actions are selected (just text). I’ve posted a script that works around this so that you can still bulk-open URLs.
- The Control-D binding for Forward Delete no longer works at all in the outline. I’ve long used that to delete actions so that I can keep my right hand on the mouse.
- You can no longer drag and drop actions onto contexts in the outline.
Design Font Smoothing iBooks Mac Mac App OmniFocus
Debug 36:
Debug is a casual, conversational interview show with the best developers in the business about the amazing apps they make and why and how they make them. On this episode Rich Siegel of Bare Bones Software talks to Guy and Rene about the journey of BBEdit from the classic Mac OS to OS X, PowerPC to Intel, 32- to 64-bit, and the direct sales to the Mac App Store.
BBEdit Business Carbon History Mac Mac App Mailsmith
Arq recently reported hundreds of GB of missing files, across multiple backup targets. This is so at odds with Amazon Glacier’s reputed 11-nines durability that I’m guessing it’s due to an application bug. It would not surprise me if the files are still there; Arq just isn’t seeing them. In any event, my strategy is to have multiple cloud backups—Arq and CrashPlan (which has been working very well recently)—so this got me thinking about possibly adding a third.
The obvious choice is Backblaze. It has a native Mac app, is developed by ex-Apple engineers, and sponsors many fine podcasts.
I’d previously been hesitant about Backblaze because of the way it handles external drives. I’ve read about problems with large bzfileids.dat files sucking RAM and preventing backups entirely once they get too large. It’s also worrisome that it only retains deleted files for 30 days—meaning that a file is truly lost if I don’t notice that it’s missing right away. And if, for some reason, my Mac doesn’t back up for 6 months, Backblaze will expunge all my data, even if my subscription is still paid-up. The situations in which my Mac is not able to back up for a while are exactly the ones in which I (or my survivors) would want to be able to depend on a cloud backup!
My other concern is that Backblaze doesn’t actually back up everything. It fails all but one of the Backup Bouncer tests, discarding file permissions, symlinks, Finder flags and locks, creation dates (despite claims), modification date (timezone-shifted), extended attributes (which include Finder tags and the “where from” URL), and Finder comments. Arq, CrashPlan (as of version 3), SuperDuper, and Time Machine all support all of these. Dropbox supports all of them except creation dates, locks, and symlinks.
As a programmer, I especially care about metadata. But I think most users would as well, if they knew to think about it. For example, losing dates can make it harder to find your files (i.e. they disappear from smart folders or sort incorrectly), even leading to errors (i.e. not finding the correct set of invoices for a time period). You would never use a backup app that didn’t remember which folders your files were in, so I don’t know why people consider it acceptable to lose their Finder tags. (If you use EagleFiler, it can restore the tags for you.)
Some people don’t care much about metadata. Macworld’s survey of online backup services didn’t mention it. Neither did Walt Mossberg. (He also told readers that Backblaze automatically includes “every user-created file”; in fact, it skips files over 4 GB by default.) [Update (2014-05-25): The Sweet Setup doesn’t mention metadata, either (via Nick Heer).]
Backblaze has a stock answer when asked about Backup Bouncer:
This actually tests disk imaging products, a bad test for backup as items we fail on shouldn’t be backed up by data backup service.
Some people accept this explanation. I think it’s misguided and borderline nonsensical. True, Backup Bouncer tests some rather esoteric features, but Backblaze fails the basic tests, too. It would be one thing to say that there’s a limitation whereby dates, tags, comments, etc. aren’t backed up, but they’re actually saying that these shouldn’t be backed up. As if products that do back them up are in error. So presumably Backblaze doesn’t consider this a bug and won’t be fixing it.
Lastly, it’s a shame that Backblaze isn’t up front about what metadata it supports. Some users are technical enough to investigate these things themselves. Others will have read the excellent Take Control of Backing Up Your Mac and seen its appendixes, which give Backblaze a C for metadata support. But most Backblaze users won’t know that a poor choice has been made for them until they need to restore from their backup.
Update (2017-08-23): A Backblaze employee responded to this post:
Backblaze absolutely backs up and restores the “file creation date” and “file last modified date”. With these two caveats: Backblaze is only accurate down to Milliseconds (1/1,000ths of a single second) if you restore by USB hard drive restore, and only accurate to the second if you prepare a ZIP file restore. The latter is because that is a limitation of the ZIP file format.
The tool “Backup Bouncer” fails Backblaze on this test, and it irritates me. I feel “wronged” by this. The new APFS Macintosh file system has the ability to set the file creation date down to one BILLIONTH of a second, and I assume that just to be totally difficult Backup Bouncer gleefully sets every last bit.
I’ve asked for clarification, but as far I can tell the response is spreading incorrect information and seems to misunderstand various of the issues involved.
I started a Backblaze trial in order to verify the claim that the creation date is preserved, but I was unable to get an answer because 4 hours after Backblaze says that it backed up my test files, they were still not showing up in the restore interface, even though it purports to show the latest files as of this minute. After 5 hours, the files were available, I restored them, and the file creation dates were lost and changed to the modification date. The Backblaze restore also messed up the files’ modes, making them executable when they had not been.
Update (2017-08-24): Backblaze support explained to me that it’s normal for there to be a delay, which can be from 1–8 hours, before the files are actually available for restore. This is because, although the file data has been sent to the server, the server can’t access the files until the client has sent the index that describes the changes. It typically waits a few hours before doing this. What this means is that, during those hours, the Backblaze client reports that the backup is complete (“You are backed up as of: Today, 7:28 AM”), but it’s actually not. If your Mac breaks or goes offline (i.e. you pack up your MacBook for a trip) before the index has been uploaded, it’s as if the backup never happened. I assume the delay before sending the index is some sort of optimization, so perhaps it’s justified, but I consider it a major bug that the client reports the files as backed up when you can’t actually restore them (no matter how long you wait).
The Backblaze employee replied about the file creation date issue. The gist of it is that the dates are not preserved when restoring via the network. However, you can pay $99 (flash drive) or $189 (hard drive) for them to mail you your data, and in this format the dates will be preserved. If you mail the drive back (sounds like you have to pay shipping) they will refund the cost. I have not verified that this method works, however, I can confirm that the index file that’s sent to the Backblaze server contains the correct information for the creation dates.
Update (2017-09-03): See also: Accidental Tech Podcast.
Update (2018-02-05): aikinai:
I started getting emails warning that all of my external drives were offline and my data would be soon deleted. Instead of “Very sorry about that, here’s how to fix the issue,” I got this long response about the ways their system looks for new files in serial and it can get jammed and start ignoring everything, with no apology, no acknowledgement this was their issue, and no solution. I had to go fishing for solutions and drag the information out of them to finally figure out what I needed to do. Which it turns out is to get back an internal drive (totally unrelated to the other drives Backblaze abandoned) I had physically removed and repurposed, put it back the computer, wait a long time for Backblaze to see it, then uncheck that drive in Backblaze and remove it again.
[…]
The client will lie to you and you never know what’s really backed up. Even if you use the secret alt-click to force a full drive scan, it can still miss files and tell you fully backed up when files from days ago are still nowhere to be found. Luckily I’ve never actually needed to do a restore, but I almost thought I did one time and would have been furious at all the missing files I noticed.
Update (2022-03-07): Backblaze (via Adam Engst, Hacker News):
Backblaze has always kept a 30-day version history of your backed up files to help in situations like these, but today we’re giving you the option to extend your version history to one year or forever.
Daniel Jalkut:
I recently learned that
@Backblaze’s 1 year extended backup doesn’t work the way I (or my brother, who ran into this) expected. I thought it was “everything just like 30 days plan - but for a year”. Instead, if you haven’t attached a drive for 30+ days you have to RE-UPLOAD it.
So the day is RETAINED for 365 days, but if you have a slow or expensive bandwidth connection, you have to make sure to re-attach drives <30 days or else you have to re-upload. Even though they have the files? Disappointing. My laziness was counting on it behaving otherwise.
Tim Wood:
I love* it when
@backblaze
says I’m fully backed up and I double-check a (non-excluded) file and see it doesn’t show up in the restore interface. Cool.
Update (2025-01-07): Wade Tregaskis:
For nearly a month now, Backblaze has been fixated on a particular file of mine, that happens to be over 1 TB in size.
[…]
Admittedly I’m guessing somewhat, since that’s a rather reader-hostile log message, but the combination of the Z_B_TOO_MANY_CHUNKS error mnemonic and chunkSeq=100001 (because of its proximity to the arbitrary round number 100,000) strongly suggests that Backblaze is imposing a 100,000 chunk limit. Since chunks are 10 MB each, that’s exactly 1 TB.
This is unequivocally at odds with what they claim repeatedly on their website, on pages like What Backblaze Backs Up and File Sizes.
Amazon Glacier Arq Backblaze Backup Cloud CrashPlan Extended Attributes Mac Mac App Metadata SuperDuper Top Posts
Wednesday, May 21, 2014
Findings from Charles Parnot et. al. looks like a neat app:
When doing science and running experiments, it is crucial to keep track of what one is doing, to be able to later reproduce the results, assemble and publish them. This is what lab notebooks are for. There is something great about paper, and the freedom and flexibility it affords. But in 2014, paper starts to show its limits in other areas where computers have taken over: storing results, analysing data, searching, replicating, sharing, preserving, and more.
Findings ambition is simple: make your computer a better tool than paper to run your experiments and keep your lab records.
Findings stores experiments, which can be organized into projects, and protocols, which cut across experiments:
Protocols are the primary building blocks of your experiments. You can drag them into the calendar view of an experiment and combine them in any way you need. Once integrated into an experiment, a copy of your protocol is made, so you can modify it just for that one use, and leave the original untouched.
It’s currently Mac-only, but they intend to add support for iOS and syncing. The storage layer, the open-source PARStore, is designed for cloud-agnostic syncing, e.g. Dropbox or iCloud document storage.
PARStore has an interesting design:
- It’s a key-value store.
- There’s one copy of the store for each device, and each device has all of the copies. The device opens its own copy read-write and the other copies read-only.
- Each copy is a log of timestamped changes, i.e. “Set key to value.” It only ever adds to the log, so there can be many entries for a given key.
- For each key, the entry with the latest timestamp is the truth. Presumably you could rewind to an earlier version of the document by searching for timestamps before a given date.
- Periodically, each device reads the other device’s logs and incorporates any changes with more recent timestamps into its own log.
- Each log is implemented as a Core Data SQLite database.
- There can also be attached files (blobs), which are stored outside of the database.
This seems like an elegant solution for synchronizing modest amounts of data, provided that it’s suited to key-value rather than row-column storage. The crux of it is that, normally, multiple devices cannot simultaneously open the same database file because SQLite’s locks don’t work across Dropbox. Or, rather, you can do it, but you’ll probably corrupt the database. PARStore gets around this by allowing multiple readers per file but only one writer. I’m not convinced that this will work 100% of the time, though:
- There doesn’t seem to be a mechanism to prevent Core Data from opening a database that Dropbox is in the process of writing to (e.g. updating it for changes made on other devices). It’s only opening it as read-only, so this shouldn’t corrupt the file, but it’s probably undefined what happens when it tries to read from the file.
- Even if the database file is fully written, there’s no telling whether the adjacent -wal and -shm files match it to form a consistent whole.
- It’s not entirely clear to me how SQLite handles read-only databases in WAL mode. The documentation implies that write access is needed. If it’s writing to the -shm file even in read-only mode, that might cause problems for the device that’s opened the database read-write.
That said, with a good Internet connection and relatively small files, I doubt that there would be many problems in practice.
Update (2014-05-30): Charles Parnot:
Findings has only been out for 8 days, and I am really proud of the launch, impressed by the response and excited about all the work that’s ahead. But before marching into the future, I thought I should look back into the past. While the core functionality of the app has remained the same, it is quite amazing to see how much of the look and the design of the app has changed over the years… I am a big fan of ‘making of’ posts on apps. I wish there were more of these, so here is one for Findings!
Core Data Findings Mac Mac App Open Source PARStore Science SQLite Syncing
Pablo Bendersky:
When you use a Migration Manager, Core Data will create a new database for you,
and start copying the entities one by one from the old DB to the new one.
As we are using journal_mode = WAL, there’s an additional file besides DB.sqlite called DB.sqlite-wal.
From what I can tell, the problem seems to be that Core Data creates a temporary DB, inserts everything
there, and when it renames it to the original name, the -wal file is kept as a leftover from the old
version. The problem is that you end up with an inconsistent DB.
A different part of Core Data is aware of the multiple files, though:
To safely back up and restore a Core Data SQLite store, you can do the following:
Use the following method of NSPersistentStoreCoordinator class, rather than file system APIs, to back up and restore the Core Data store:
- (NSPersistentStore *)migratePersistentStore:(NSPersistentStore *)store toURL:(NSURL *)URL options:(NSDictionary *)options withType:(NSString *)storeType error:(NSError **)error
Note that this is the option we recommend.
Change to rollback journaling mode when adding the store to a persistent store coordinator if you have to copy the store file.
Bug Cocoa Core Data iOS Mac Programming SQLite
duhanebel:
The implementation for x86_64 on NSObject.mm is quite straightforward. The code analyses the assembler located after the return address of objc_autoreleaseReturnValue for the presence of a call to objc_retainAutoreleasedReturnValue.
But for ARM:
It looks like the code is identifying the presence of objc_retainAutoreleasedReturnValue not by looking up the presence of a call to that specific function, but by looking instead for a special no-op operation mov r7, r7.
Bill Bumgarner:
ARM’s addressing modes don’t really allow for direct addressing across the full address space. The instructions used to do addressing -- loads, stores, etc… -- don’t support direct access to the full address space as they are limited in bit width.
Greg Parker:
A resolved dyld stub is simple on Intel: it’s just a branch to a branch. On ARM the instruction sequences for the branch to the stub and the branch from the stub can take many different forms depending on how long the branches are. Checking for each combination would be slow.
Automatic Reference Counting (ARC) Objective-C Optimization Programming
Joe Kissell:
Things turned around in 2011 with the release of Nisus Writer Pro 2.0. This was the first version of Nisus Writer to include both change-tracking and comments, plus most of my favorite features from Nisus Writer Classic and a bunch of new capabilities. All of a sudden I had my old toolkit back, in a modern package. It was as though I’d been limited to a machete and an open fire for all my cooking needs, and then walked into a fully equipped restaurant kitchen. In the years since, it has grown even more capable and reliable.
Eventually Take Control Books switched its entire operation over to Nisus Writer Pro, and I’ve already used it to write half a dozen books, plus new editions of several older titles. As an author, I can’t overstate how much Nisus Writer Pro improves not only my productivity but also my attitude toward writing. It’s fun again, and I no longer feel as though I must constantly fight with my word processor.
I really like Nisus Writer, but these days almost all of my writing is in reStructuredText (to be processed for product documentation), direct HTML (for online), plain text notes (for syncing with my iPhone), or in Word or Google Docs (for collaboration). Nisus Writer just doesn’t seem to fit in, though I still find it invaluable for the occasional project where I need to process lots of styled text.
Mac Mac App Nisus Writer Pro reStructuredText Word Processing
USA Today:
Online marketplace eBay says it will urge users to change their passwords following a “cyberattack” impacting a database with encrypted passwords and non-financial data.
The database includes information such as customers’ names, encrypted passwords, email and physical addresses, phone numbers and dates of birth.
[…]
EBay also was using a more easily-cracked method for protecting the passwords it kept on file. There are two commonly used ways to secure passwords, encryption and hashing. EBay was using encryption, which is the more easily broken, said Coates.
“Encryption allows eBay, or anyone who access the decryption key, to decrypt and see your actual password. Password hashing allows eBay to check if the password you enter is correct or not, but doesn’t allow eBay (or hackers) to get the plaintext of your actual password,” he said.
The Verge:
In addition to passwords, the database contained basic login information like name, email, phone number, address and date of birth, but officials stressed that, aside from the passwords, no confidential or personal information was included in the breach.
That’s an odd way of putting it, since those pieces of data are exactly what show up on the “Personal Information” page of my eBay account.
Update (2014-05-25): eBay:
All eBay users are being asked to change their password. All eBay users will be notified. At the end of Q1, we had 145 million active buyers.
The Daily Beast:
The online auction site eBay has admitted that the name, address, date of birth, telephone number, email address and encrypted password of every eBay account holder worldwide – 233 million people – have been obtained by hackers, in one of the world’s largest ever online security breaches.
Update (2014-05-26): I finally received an e-mail from eBay recommending that I reset my password.
Breach Change Your Password eBay Privacy Security Web
I had assumed that dispatch_once() was implemented as a basic atomic compare-and-swap, but the source for dispatch_once_f contains an interesting comment:
Normally, a barrier on the read side is used to workaround
the weakly ordered memory model. But barriers are expensive
and we only need to synchronize once! After func(ctxt)
completes, the predicate will be marked as “done” and the
branch predictor will correctly skip the call to
dispatch_once*().
A far faster alternative solution: Defeat the speculative
read-ahead of peer CPUs.
Modern architectures will throw away speculative results
once a branch mis-prediction occurs. Therefore, if we can
ensure that the predicate is not marked as being complete
until long after the last store by func(ctxt), then we have
defeated the read-ahead of peer CPUs.
In other words, the last “store” by func(ctxt) must complete
and then N cycles must elapse before ~0l is stored to *val.
The value of N is whatever is sufficient to defeat the
read-ahead mechanism of peer CPUs.
On some CPUs, the most fully synchronizing instruction might
need to be issued.
N is determined by dispatch_atomic_maximally_synchronizing_barrier(), which has different assembly language implementations for different architectures.
Update (2014-05-28): Greg Parker explains a consequence of this optimization:
dispatch_once_t must not be an instance variable.
The implementation of dispatch_once() requires that the dispatch_once_t is zero, and has never been non-zero. The previously-not-zero case would need additional memory barriers to work correctly, but dispatch_once() omits those barriers for performance reasons.
Instance variables are initialized to zero, but their memory may have previously stored another value. This makes them unsafe for dispatch_once() use.
Update (2014-06-06): Mike Ash:
While the comment in the dispatch_once source code is fascinating and informative, it doesn’t quite delve into the detail that some would like to see. Since this is one of my favorite hacks, for today’s article I’m going to discuss exactly what’s going on there and how it all works.
Assembly Language C Programming Language Concurrency Grand Central Dispatch (GCD) iOS Mac Open Source Optimization Programming
Tuesday, May 20, 2014
Daniel Jalkut:
On the other hand, MarsEdit features a rich HTML text editor largely implemented in JavaScript, a language which tends not to afford any of these convenient alerts to my mistakes. I have often stared in bewilderment as the editor window’s perplexing behavior, only to discover after many lost minutes or hours, that some subtle JavaScript error has been preventing the expected behavior of my code. I’ll switch to the WebKit inspector for the affected WebView, and discover the console is littered with red: errors being dutifully logged by the JavaScript runtime, but ignored by everybody.
Wouldn’t it be great if the JavaScript code crashed as hard as the Objective-C code does?
His solution is to add a JavaScript event listener that reports errors to the Objective-C delegate object.
Cocoa JavaScript Mac Objective-C Programming WebKit
Monday, May 19, 2014
Version 2.4 of Indeeo’s iDraw (Mac App Store) adds support for code generation:
Copy vector shapes and effects directly as Core Graphics drawing code. Convert fully-styled buttons and icons into CGContext code, automatically generating CGPaths, CGColors, CGGradients, etc. Directly use the generated code in both Mac and iOS projects.
Even convert multi-style text objects into CFAttributedStrings, along with Core Text layout and drawing code.
Now you can turn app design mockups instantly into readily useable code.
C Programming Language Code Generation Graphics iDraw Mac Mac App Quartz
Nicolas Bouilleaud:
What? Nil objects don’t have a class; they’re just nil pointers. _ivarDescription prints the expected class of the instance variable, as specified in the source code.
In fact, the compiler stores extended type info in the binary. That’s really weird: Objective-C treats all objects equals, as ids, and will not complain when assigning an object of a class to a pointer of a different type. I always assumed that class info was lost at runtime; it turns out that’s not true.
[…]
As with ivars, methods arguments expect objects of a specific class, and this information is embedded in the binary. For some reason, it’s only available for methods declared in Protocols, and the public runtime API won’t let us access it, but the private function _protocol_getMethodTypeEncoding() will do.
Maybe someday the runtime will be able to access annotations, too…
iOS Mac Objective-C Objective-C Runtime Programming
Geoff Duncan:
FCC Chairman Tom Wheeler says the proposed rules are all about preserving net neutrality. However, in practice the proposed regulations are trying to walk a fine line between net neutrality principles and the business concerns of American broadband providers. And while everyone seems to think net neutrality is a good idea — publicly, at least — almost everybody also seems to hope the FCC’s latest effort will fail.
Federal Communications Commission (FCC) Network Neutrality
Friday, May 16, 2014
Christopher Breen:
In the recent release of iTunes 11.2 and OS X 10.9.3, Apple brought a measure of joy to those users who missed the ability to sync contacts and calendars over a tethered USB connection. Gone since the introduction of OS X Mavericks, its reintroduction will be welcomed by those who don’t care to sync this kind of data over iCloud.
Christopher Breen:
One unexpected consequence of the recent OS X 10.9.3 update is that the Users folder at the root level of the startup volume is hidden from some users, though not all. I was among them. When installing the 10.9.3 update available from the App Store on both my 2009 Mac Pro and late 2012 MacBook Air, the Users folder was indeed missing. Yet I’ve heard from a couple of colleagues and several people on Twitter that their Users folders remain visible.
[…]
Fortunately, there’s an impermanent solution to the problem. Launch Terminal (/Applications/Utilities), enter sudo chflags nohidden /Users, and press the Return key. You’ll be prompted for your user password. Enter it, press Return again, and the Users folder will be visible as it once was.
Dave Hamilton:
Turns out that hidden /Users folder has nothing to do with OS X 10.9.3. Your /Users and /Users/Shared folders will be hidden by OS X upon every reboot of your Mac if you have updated to iTunes 11.2 and have Find My Mac enabled.
[…]
One of our readers indicated that Apple said this is intentional. If it were in 10.9.3 I would believe it. But seeing as how it’s part of an iTunes update, I’m not sure.
Update (2014-05-19): Jeff Johnson:
How do you even accidentally put a bug in iTunes that hides the /Users folder? I would like to see that code.
Apple (via Dave Mark):
Upon each reboot, the permissions for the /Users and /Users/Shared directories would be set to world-writable, allowing modification of these directories. This issue was addressed with improved permission handling. For information on the general content of iTunes 11.2.1, see http://support.apple.com/kb/TS5434.
Xlr8YourMac in 2001 (via Nick Heer):
Apple has identified an installer issue with iTunes 2.0 for Mac OS X that affects a limited number of systems running Mac OS X with multiple volumes (drives or partitions) mounted. For those systems, running the iTunes 2.0 installer can result in loss of user data.
Bug File Permissions iOS iTunes Mac Mac OS X 10.9 Mavericks Syncing
Thursday, May 15, 2014
Daniel Jalkut:
Today I decided that I need to stop manually copying and pasting these commands, and I need to finally learn the slightest bit about lldb’s Python-based script commands. The fruit of this effort is summarized in this GitHub gist. Follow the directions on that link, and you’ll be no further away than typing “fsa” in lldb from having all of its utility instantly injected into the attached app from lldb.
Debugging Developer Tool F-Script Anywhere LLDB Mac Programming Python
Dropbox:
In general, a webhook is a way for an app developer to specify a URI to receive notifications based on some trigger. In the case of Dropbox, notifications get sent to your webhook URI every time a user of your app makes a file change. The payload of the webhook is a list of user IDs who have changes. Your app can then use the standard delta method to see what changed and respond accordingly.
This got me thinking about how I thought that Apple had at one point talked about Web APIs for iCloud. I couldn’t find a reference for that, but I did find the WWDC 2011 keynote where Steve Jobs says (at 96:33):
Documents and Key Value data works across all iOS devices and Macs and PCs, too.
I don’t see any evidence that this shipped, though.
Cloud Dropbox iCloud Web API Windows
Brian Beach (via Josh Centers):
Google and Microsoft have both done studies on disk drive temperature in their data centers. Google found that temperature was not a good predictor of failure, while Microsoft and the University of Virginia found that there was a significant correlation.
Disk drive manufacturers tell Backblaze that in general, it’s a good idea to keep disks cooler so they will last longer.
[…]
After looking at data on over 34,000 drives, I found that overall there is no correlation between temperature and failure rate.
[…]
Each Storage Pod in our data center is initially deployed with one model of drive in all 45 slots. It tends to stay that way over time, too, as drives are replaced. Pods with different models of drives are distributed somewhat randomly around the data center, so on the average, each model runs in an environment that is about the same. The temperatures in the table above are due to differences in the disk drives more than differences in their environment.
Backblaze Backup Hardware Storage
Benjamin Mako Hill (via Josh Centers):
Peter pointed out that if all of your friends use Gmail, Google has your email anyway. Any time I email somebody who uses Gmail — and anytime they email me — Google has that email.
[…]
Despite the fact that I spend hundreds of dollars a year and hours of work to host my own email server, Google has about half of my personal email!
E-mail Gmail Google Privacy
David Streitfeld:
The uneasy relationship between the retailer and the writing community, which needs Amazon but fears its power, immediately soured as authors took to Twitter to denounce what they saw as bullying.
Among Amazon’s tactics against Hachette, some of which it has been employing for months, are charging more for its books and suggesting that readers might enjoy instead a book from another author. If customers for some reason persist and buy a Hachette book anyway, Amazon is saying it will take weeks to deliver it.
The scorched-earth tactics arose out of failed contract negotiations. Amazon was seeking better terms, Hachette was balking, so Amazon began cutting it off.
Update (2014-05-28): Amazon Books team (via Kontra):
Negotiating with suppliers for equitable terms and making stocking and assortment decisions based on those terms is one of a bookseller’s, or any retailer’s, most important jobs. Suppliers get to decide the terms under which they are willing to sell to a retailer. It’s reciprocally the right of a retailer to determine whether the terms on offer are acceptable and to stock items accordingly. A retailer can feature a supplier’s items in its advertising and promotional circulars, “stack it high” in the front of the store, keep small quantities on hand in the back aisle, or not carry the item at all, and bookstores and other retailers do these every day. When we negotiate with suppliers, we are doing so on behalf of customers. Negotiating for acceptable terms is an essential business practice that is critical to keeping service and value high for customers in the medium and long term.
They recommend this post from Martin Shepard:
I always have a lingering suspicion that when one of the
large publishing cartels complains they are being treated unfairly by Amazon,
it’s probably good for most all of the smaller, independent presses. When the Times allows a poorly researched,
inaccurate anti-Amazon screed to appear, it makes me want to stand up for Jeff
Bezos and Amazon, and present a very different point of view which I hope will
balance out what I consider blatant propaganda. And I would encourage other
publishers who feel similarly to email me and speak out as well.
Update (2014-06-13): David Streitfeld (via John Gruber):
The Everything Store is shrinking again. Amazon customers who want
to order forthcoming Warner Home Video features, including The
Lego Movie, 300: Rise of an Empire, Winter’s Tale and
Transcendence, are finding it impossible to do so.
The retailer’s refusal to sell the movies is part of its effort to
gain leverage in yet another major confrontation with a supplier
to become public in recent weeks.
Update (2014-06-14): Joe Nocera:
The story really began some years ago, when Amazon began issuing a standard price for e-books of $9.99 — in some cases selling below cost. Publishers feared that they would become locked into the $9.99 price the same way the music industry had been locked into 99-cent songs by Apple’s iTunes service. They fought back by joining forces with Apple, cutting preferable deals to participate in Apple’s e-book-selling service, and then forcing Amazon to go along with the same terms. E-book prices quickly rose.
Unfortunately for the publishers, their brilliant idea turned out to be an illegal conspiracy, and the government forced them to settle on terms that had the effect of boosting Amazon. Although Amazon has not entirely reverted back to $9.99 e-books, it could if it wanted to, and it has in some cases.
Update (2014-06-18): Hugh C. Howey:
Ironically, the biggest losers in this shift have been yesterday’s villains. The massive brick and mortar discounters—who once were blamed for literature’s downfall, who sold “loss leaders,” who roughed up publishers in negotiations—have become the bulwark behind which all legacy hopes now hunker. Little explored is the possibility that Amazon is helping independent bookstores by clearing out these former predators.
[…]
Similarly, the merger between Penguin and Random House has created a mega conglomerate that accounts for half of the major publishers’ revenue. There was very little outrage at this merger, which will result in lost jobs and fewer places for authors and manuscripts to compete. Instead, we heard how greater efficiency will help these grand institutions compete with that evil company trying to lower prices and raise author pay. Again, who is the monopoly?
[…]
The real monopoly, once you start examining business practices and attitudes, is Big Publishing itself, a group so entrenched with one another and indistinguishable from one another that they simply go by the collective moniker: The Big 5.
Their contracts are functionally identical. Their e-book royalties (and most others terms and clauses) are lockstep and are not negotiable. They have a history of working together in a noncompetitive fashion in order to raise prices for their customers (prices that they would love to set at twice what mass market paperbacks formerly cost).
[…]
The response to this new competitor has been to blacklist Amazon-published books from brick and mortar stores and to collusion within the publishing monoculture. Where is the outcry for Amazon-published authors who are blocked from sale by practically every brick and mortar store? It doesn’t exist. The response is simply: That’s what those authors get for signing with Amazon. Imagine an observer today saying “That’s what those authors get for signing with Hachette.” The hypocrisy astounds.
[…]
Why show support for a corporation that may lower royalties to 30% in the future when you can celebrate a corporation that pays 17.5% today? Why show support for a corporation that may raise prices in the future when you can champion a corporation that colludes to raise them today?
Amazon Books Business E-books Hachette
Wednesday, May 14, 2014
Filip Pizlo:
This post describes a new advancement in JavaScript optimization: the WebKit project has unified its existing JavaScript compilation infrastructure with the state-of-the-art LLVM optimizer. This will allow JavaScript programs to leverage sophisticated optimizations that were previously only available to native applications written in languages like C++ or Objective-C.
[…]
As we worked to improve WebKit’s optimizing compiler, we found that we were increasingly duplicating logic that would already be found in traditional ahead-of-time (AOT) compilers. Rather than continue replicating decades of compiler know-how, we instead investigated unifying WebKit’s compiler infrastructure with LLVM – an existing low-level compiler infrastructure. As of r167958, this project is no longer an investigation. I’m happy to report that our LLVM-based just-in-time (JIT) compiler, dubbed the FTL – short for Fourth Tier LLVM – has been enabled by default on the Mac and iOS ports.
[…]
The WebKit FTL JIT is the first major project to use the LLVM JIT infrastructure for profile-directed compilation of a dynamic language. To make this work, we needed to make some big changes – in WebKit and LLVM. LLVM needs significantly more time to compile code compared to our existing JITs. WebKit uses a sophisticated generational garbage collector, but LLVM does not support intrusive GC algorithms. Profile-driven compilation implies that we might invoke an optimizing compiler while the function is running and we may want to transfer the function’s execution into optimized code in the middle of a loop; to our knowledge the FTL is the first compiler to do on-stack-replacement for hot-loop transfer into LLVM-compiled code.
Unfortunately, it sounds like these optimizations—like those in Nitro—will not be available to third-party iOS apps.
Update (2014-07-17): Andrew Trick:
FTL makes it clear that LLVM can be used to accelerate a dynamically type checked languages in a competitive production environment. This in itself is a tremendous success story and shows the advantage of the highly modular and flexible design of LLVM. It is the first time that the LLVM infrastructure has supported self-modifying code, and the first time profile guided information has been used inside the LLVM JIT. Even though this project pioneered new territory for LLVM, it was in no way an academic exercise. To be successful, FTL must perform at least as well as non-FTL JavaScript engines in use today across a range of workloads without compromising reliability. This post describes the technical aspects of that accomplishment that relate to LLVM and future opportunities for LLVM to improve JIT compilation and the LLVM infrastructure overall.
Code in App Store iOS JavaScript Just-In-Time Compilation (JIT) LLVM Mac Optimization WebKit
Here’s the video and paper (via Matthew Guay):
We present Cider, an operating system compatibility architecture that can run applications built for different mobile ecosystems, iOS or Android, together on the same smartphone or tablet. Cider enhances the domestic operating system, Android, of a device with kernel-managed, per-thread personas to mimic the application binary interface of a foreign operating system, iOS, enabling it to run unmodified foreign binaries. This is accomplished using a novel combination of binary compatibility techniques including two new mechanisms: compile-time code adaptation, and diplomatic functions. Compile-time code adaptation enables existing unmodified foreign source code to be reused in the domestic kernel, reducing implementation effort required to support multiple binary interfaces for executing domestic and foreign applications. Diplomatic functions leverage per-thread personas, and allow foreign applications to use domestic libraries to access proprietary software and hardware interfaces. We have built a Cider prototype, and demonstrate that it imposes modest performance overhead and runs unmodified iOS and Android applications together on a Google Nexus tablet running the latest version of Android.
See also the discussion on Hacker News.
Android Cider iOS
Cabel Sasser:
Coda 2.5 is essentially complete. But, we’re still encountering sandboxing challenges. So, in the interest of finally getting Coda 2.5 out the door and in the hands of you, our very eager and patient customers, we’ve decided it’s time to move on—for now.
In short: Coda 2.5 will not be sandboxed, and therefore will not be available in the Mac App Store.
Recall that the original sandboxing deadline was in November 2011, shortly after the release of Mac OS X 10.7. Apple has yet to even document which APIs work in the sandbox, and there remain standard Cocoa ones that don’t. The elite Panic engineers have been working on this for years—with special help, workarounds, and exemptions from Apple—but it still doesn’t work. How many developer hours have been wasted on the sandboxing debacle?
iCloud requires the App Store, so that’s out. But we have great news. We never want to short-change our paying customers, so we’ve spent many months working on Panic Sync, our own super-easy, super-secure syncing solution that gives you power over your data.
It sounds as though Panic Sync was developed not just because of the App Store, but also because of problems with iCloud. I’m sure this is the right thing for Panic’s customers, just like Omni Sync Server was for Omni’s. But it’s sad that this sort of thing is needed.
Coda iCloud Mac Mac App Mac App Store Panic Panic Sync Sandboxing
Adam Pash (via David Heinemeier Hansson):
I recently switched from an iPhone to Android, and discovered shortly thereafter that my phone number was still associated with iMessage, meaning that any time someone with an iPhone tried texting me, I’d receive nothing, and they’d get a “Delivered” receipt in their Messages app as though everything were working as expected.
[…]
In the meantime, Apple has completely hijacked my text messaging and my phone number portability (portability between devices, not networks). No one can fix this but Apple because it’s a problem at the device level, which means people in my position have no recourse but to wait for Apple to figure out what the problem is. But Apple isn’t offering any public support on the issue that I’ve been able to find (and it’s worth repeating that proper support is behind a $20 paywall for most people who’ve switched devices, who would also be the most commonly affected by this problem).
Kif Leswing:
This isn’t a new problem, and Apple’s got several support pages and forum threads addressing it. Here’s one updated April 29 of this year called “Deactivating iMessage.” Of course, it says if you no longer have the device, you’ll be sent into an Apple Support labyrinth like the one Pash encountered.
I understand that Apple thinks this is a minor problem and that most iPhone customers end up being repeat customers, but it is a statistical certainty that there will be iPhone customers who want to keep their phone number and also want to switch to another platform, whether it’s Android, Windows Phone, Firefox OS, or something that hasn’t even been invented yet. The problem is only going to become more widespread.
Apple Bug iMessage iOS iPhone
Tuesday, May 13, 2014
Matthew Guay:
No, the Omni Group hasn’t decided to go cross platform and release their apps for Android, but yes, there’s now a way to get your OmniFocus database on Android: Quantus Tasks. A brand new app that was originally named AndroidFocus that was quickly renamed to avoid confusion, Quantas Tasks lets you view all of your OmniFocus projects and tasks on your Android device, add new tasks, and more. It doesn’t support attachments or recurring tasks yet, but the developer’s promised to add that soon.
This is possible because of the open file format that OmniFocus uses. Now I’m no longer sure which app I’d miss the most if I switched to Android.
Android Android App OmniFocus Quantus Tasks
Monday, May 12, 2014
Nicholas Carlson:
The speech surprised the Google executives, particularly the company veterans. Since the days of Page and Brin calling every idea they didn’t like “stupid” — if not “evil” — fighting was the way things got done at Google.
Some of them remembered that day in July 2001 when Page had insulted and fired a handful of project managers in front of all their peers. But when the people in the Carneros Inn ballroom looked at Page that day, they saw someone who looked very different from the kid who built Google’s first server rack in his dorm room.
Google History Larry Page Marissa Mayer
Kenny Carruthers:
I’ve considered manually throttling the requests with an NSOperationQueue and a low value for the maxConcurrentOperationCount but that just seems wrong as the newer MacPros can clearly handle a ton more I/O compared to an older, non-SSD, MacBook.
Bill Bumgarner:
The reality is that a modern, multi-tasking, multi-user system that runs across many configurations of hardware, automatically throttling an I/O bound task is nigh impossible for the system to do.
You’re going to have to do the throttling yourself. This could be done with NSOperationQueue, with a semaphore, or with any of a number of other mechanisms.
Normally, I’d suggest you try to separate the I/O from any computation so you can serialize I/O (which is going to be the most generally reasonable performance across all systems), but that is pretty much impossible when using high level APIs. In fact, it isn’t clear how the CG* I/O APIs might interact with the dispatch_io_* advisory APIs.
I like GCD, but you have to take its promise with a huge grain of salt:
In the past, introducing concurrency to an application required the creation of one or more additional threads. Unfortunately, writing threaded code is challenging. Threads are a low-level tool that must be managed manually. Given that the optimal number of threads for an application can change dynamically based on the current system load and the underlying hardware, implementing a correct threading solution becomes extremely difficult, if not impossible to achieve.
[…]
Rather than creating threads directly, applications need only define specific tasks and then let the system perform them. By letting the system manage the threads, applications gain a level of scalability not possible with raw threads.
You still have to manage things manually unless you’re not doing I/O. It’s just that you’re dealing with queues rather than threads. And we don’t yet have good tools for adapting code to systems with different I/O capabilities.
Concurrency Grand Central Dispatch (GCD) iOS Mac Programming
Mike Ash tries to use sel_getUid() to work around not being able to call -autorelease from ARC code and runs into some interesting issues:
I also said that this code is not harmless. The harm here is exactly that fast autorelease path. To ARC, an autorelease in a function or method followed by a retain in the caller is just a way to pass ownership around. However, that’s not what’s going on in this code. This code is attempting to actually put the object into the autorelease pool no matter what. ARC’s clever optimization ends up bypassing that attempt and as a result, the dictionary is immediately destroyed instead of being placed in the autorelease pool for later destruction.
[…]
References to external functions aren’t fully bound when a program is initially loaded. Instead, a stub is generated which has enough information to complete the binding the first time the call is made. On the first call to an external function, the address for that function is looked up, the stub is rewritten to point to it, and then the function call is made. Subsequent calls go directly to the function. By binding lazily, program startup time is improved and time isn’t wasted looking up functions that are never called.
Since CFAutorelease() requires Mac OS X 10.9, Daniel Jalkut suggests implementing your own function in a file that’s not compiled with ARC:
CFTypeRef MAAutorelease(CFTypeRef CF_RELEASES_ARGUMENT arg)
{
return [(id)arg autorelease];
}
This is probably the “right” solution, but it’s kind of a pain.
Tammo Freese suggests:
inline CFTypeRef MyAutorelease(CFTypeRef obj) {
id __autoreleasing result = CFBridgingRelease(obj);
return (__bridge CFTypeRef)result;
}
The behavior of the __autoreleasing ownership qualifier is really subtle, though.
All of this illustrates the leakiness of the ARC abstraction. For simple cases, everything just works, without your having to know how. But at some point you not only have to understand the manual memory management rules that you were avoiding; you also have to understand the calls the compiler is inserting on your behalf and the crazy per-architecture optimizations. With manual memory management, we debugged using tools like ObjectAlloc and Instruments. With ARC, you occasionally need to drop into assembly.
Assembly Language Automatic Reference Counting (ARC) Cocoa dyld Memory Management Objective-C Programming
Brent Simmons:
Somewhere along the way the decision was made to shut down the consumer browser-based app and the syncing platform.
[…]
Last things to note: even Google Reader is gone. And AllThingsDigital.
Meanwhile, RSS is alive and well (from 2013), as always.
Dave Winer:
I always wondered what the VCs were thinking. They had a chance to work with the guy who was driving adoption, who had the relationships with the publishers, and had a roadmap already worked out. Instead they went with a nice guy who thought RSS was email.
Business History Mac Mac App NetNewsWire NewsGator RSS Sunset
Jon Maples (via John Gruber):
The first number [13.3] is the percentage that music downloads have decreased in Q1 of this year compared with 2013. This is on the heels of a 5% decrease last year, so it’s looking like the decline is picking up speed.
[…]
It’s pretty clear when it comes to the choice between buying downloads or using a streaming service, customers are beginning to choose streaming. But so far, Apple has sat out of the subscription music trend. After all, the Book of Jobs says that customers wanted to own rather than rent music.
I thought Jobs was right about this. I don’t want to have to subscribe to anything. But clearly lots of people think otherwise. Maples suggests that Apple would keep the streaming service separate from iTunes, as a hedge.
Apple Beats Music Business iTunes Store Music Steve Jobs
Saturday, May 10, 2014
Reuters:
The case examined whether computer language that connects programs - known as application programming interfaces, or APIs - can be copyrighted. At trial in San Francisco, Oracle said Google’s Android trampled on its rights to the structure of 37 Java APIs.
U.S. District Judge William Alsup ruled that the Java APIs replicated by Google were not subject to copyright protection and were free for all to use. The Federal Circuit disagreed on Friday, ruled for Oracle and instructed the lower court to reinstate a jury’s finding of infringement as to 37 Java API packages.
[…]
The unanimous Federal Circuit panel ordered further proceedings before Alsup to decide whether Google’s actions were protected under fair use.
Florian Mueller:
The Federal Circuit disagrees with the district court and Google (the district court had basically just adopted Google’s fundamentally flawed non-copyrightability argument, which is why it just got overruled) on the point in time at which the theory of a “merger” (of idea and expression) has to be determined. Google argued that it had only one way to write those API declarations -- but that’s because it chose to be similar to Java in certain (and not all) respects. But this way Google limited its own choice. It could have create completely new APIs for Android. The question in a copyright case is, however, not whether the copyist had choices. It’s whether the creator of the copied material had options. And Sun’s engineers (Java was developed by Sun, which was acquired by Oracle in 2010) had plenty of choices. The Java APIs were and are creative and original. And that’s why they are protected. Otherwise something could be protected by copyright when it’s written and then lose copyright protection later because someone choose to copy -- that would be absurd.
Florian Mueller:
Within the context of the “smartphone IP wars”, yesterday’s appellate opinion in Oracle v. Google was spectacular. An unprecedented comeback. Oracle now has more legal leverage over Google than anyone else, such as Apple, has ever had, even at this stage, where things may still take a couple of years before an injunction issues (and, of course, there is some uncertainty remaining with “fair use”, though the Federal Circuit made certain limits of that defense clear as well).
[…]
Both Sega and the subsequent Sony v. Connectix case -- fair use and not copyrightability cases -- did not establish an interoperability exception to copyrightablity, as the Federal Circuit clarified but Google’s supporters still don’t want to recognize. I already addressed that one two years ago. The problem with reading Sega (which Sony is based on) as holding anything related to compatibility to be non-copyrightable is that this is not even an obiter dictum. It’s simply not stated at all unless one takes a few words out of context.
[…]
In Sega, interoperability was considered a laudable goal. Yes, it is. That fact weighs in favor of fair use. In that case, it did. Rightly so. So if you only do a few intermediate copies for yourself and you copy 20-25 bytes (a mere identifier), and that’s what it takes to bring more games to consumers for a platform they’ve purchased, that may be fine. In that case, it was. Rightly so. But the Ninth Circuit (the West Coast circuit) didn’t say that anything relating to compatibility -- which would require some very complex line-drawing if it was the law (which it is not) -- is by definition non-copyrightable.
Jon Galloway:
Wow, so Google actually considered rebuilding Android on .NET and C# back in 2005.
The complete opinion is available here (PDF, via Mark Lemley).
See also API Copyrightability.
Update (2014-05-12): Robert McMillan:
Predictably, Google is unhappy. “We’re disappointed by this ruling, which sets a damaging precedent for computer science and software development, and are considering our options,” Google said in an emailed statement. But open source developers aren’t too happy about it either. In a post to the online discussion site Hacker News, Bryan Cantrill, the CTO at cloud provider Joyent, called the idea that APIs could be copyrighted a “perverted and depraved principle.”
“An API is a description of what the software is going to do,” Cantrill tells us. “You can think of the API as the plot as opposed to the novel. If you’re saying that that abstract notion of the plot is copyrightable, then everything is derivative.”
According to Cantrill, Oracle shouldn’t exactly be crowing about its court victory. Cantrell works on an open-source version of the Solaris operating system, and he says that Oracle copied some of his APIs into its Oracle Solaris product without permission.
Copyright Google Java Legal Oracle
Thursday, May 8, 2014
Instapaper:
Today, we’re happy to announce that we’ve shipped text highlighting across all of our platforms — iOS, Android, and web! Now you can just select some text and choose the “Highlight” option to save those great quotes you find while reading.
In true Instapaper fashion, your highlights are seamlessly synced across all of your devices. We’ve also added the option for you to post automatically your highlights to your linked accounts.
You get five free highlights per month if you haven’t subscribed. Highlighting is supported in the API. Two features I hope they will add are:
- More control over the background color (in the article reader and browser), since iOS doesn’t support Flux.
- Automatic retries for articles that haven’t been downloaded. I waste so much time tapping individual articles that can’t be read.
Instapaper iOS iOS App Web
John Brownlee:
This is where we get the terms typeface and font. In the example above, Garamond would be the typeface: It described all of the thousands of metal blocks a printer might have on hand and which had been designed with the same basic design principles. But a font was something else entirely. A font described a subset of blocks in that very typeface--but each font embodied a particular size and weight. For example, bolded Garamond in 12 point was considered a different font than normal Garamond in 8 point, and italicized Times New Roman at 24 point would be considered a different font than italicized Times New Roman at 28 point.
Font Typography
Wednesday, May 7, 2014
Dropbox (via Slashdot):
We wanted to let you know about a web vulnerability that impacted shared links to files containing hyperlinks. We’ve taken steps to address this issue and you don’t need to take any further action.
For background, whenever you click on a link in any browser, the site you’re going to learns where you came from by something called a referer header. The referer header was designed to enable websites to better understand traffic sources. This is standard practice implemented across all browsers.
Their remedy, breaking any existing shared links, seems to be worse than the problem it’s trying to solve.
Dropbox Security Web
Google Maps adds a bunch of new features, including lane guidance, saving maps for offline use, Uber integration, and train schedules (via Christian Zibreg). It also finally adds integration with the iOS Contacts database, although this is only via search. There is unfortunately no way to browse your contacts from within Google Maps. Nor can you browse in the Contacts app and open maps in Google Maps, since it’s hard-coded to use Apple Maps.
Contacts Google Maps iOS iOS App Maps
Tuesday, May 6, 2014
Dalton Caldwell:
The bad news is that the renewal rate was not high enough for us to have sufficient budget for full-time employees. After carefully considering a few different options, we are making the difficult decision to no longer employ any salaried employees, including founders. Dalton and Bryan will continue to be responsible for the operation of App.net, but no longer as employees. Additionally, as part of our efforts to ensure App.net is generating positive cash flow, we are winding down the Developer Incentive Program.
[…]
Today we are launching a new open source page at opensource.app.net. The first new piece of software we are open sourcing is our microblogging web application, Alpha. The source code to Alpha is available here.
Marco Arment:
They’re putting on a good face, but it sure sounds like it’s over. It now has no full-time staff, very little money, and even less motivation for developers to write apps for it — and that’s just after the first major renewal period.
Christopher Poole:
I found myself in the same exact position with Canvas/DrawQuest earlier this year. Everyone (including myself) was laid off a few months ago, but we'd hoped to keep the app running with the remaining revenue/cash-on-hand and volunteered time (cut short by a recent hack).
App.net Business Django Open Source Python Web Web API
Kirby Turner:
Because I use Auto Layout in code I realized overtime I was using Interface Builder only to define the UI elements that made up the view. I would define all the Auto Layout constraints in code. This got me thinking, why do I need to define the UI elements in IB? So I did a small project with no NIBs or storyboards, and I loved it. I felt more productive, and I was banging my head against the wall a hell of a lot less.
[…]
I’ve now done a number of iOS projects where I don’t use a single NIB or storyboard, and I’m convinced this is the right approach for me. I see everything regarding a view and its subviews explicitly defined in source code, which makes it easier to see what’s going on and to make changes. No more bouncing between inspectors to figure out what is causing a problem or to understand how a view is rendered. I see it all in the source code defined in a single .m file.
Code is also much better at factoring out common sub-layouts and localized strings.
Auto Layout Cocoa Interface Builder iOS Mac Programming
Aspects:
Delightful, simple library for aspect oriented programming by @steipete.
Think of Aspects as method swizzling on steroids. It allows you to add code to existing methods per class or per instance, whilst thinking of the insertion point e.g. before/instead/after. Aspects automatically deals with calling super and is easier to use than regular method swizzling.
[…]
An important limitation is that for class-based hooking, a method can only be hooked once within the subclass hierarchy.
[…]
KVO works if observers are created after your calls aspect_hookSelector: It most likely will crash the other way around.
Aspect-Oriented Programming (AOP) Objective-C Open Source Programming
Frax (App Store: iPhone, iPad) from Kai Krause et al. (via Michael Yacavone):
20 years ago this team created a fractal explorer called ‘Frax’ and became curious “What could we do on an iPhone today?“
The reborn Frax, now orchestrating new algorithms in an intricate dance between CPU and GPU is literally… 400 times faster!
Totally immersive in realtime you can now zoom into more
than a trillion-to-one depth range of the classic Mandelbrot set and,
for the first time ever, the more self-similar Julia sets can be zoomed… infinitely!
The rendering and interactivity are striking. It also has an interesting use of In-App Purchase:
The Frax Cloud is the online counterpart of the Frax app. The cloud provides access to the Frax Render Farm, which is used to create high resolution images from your Frax presets at a much higher quality and size than is possible from within the app.
Frax In-App Purchase iOS iOS App
Thursday, May 1, 2014
Alex Guyot:
Since no single resource has previously existed to bring you up to speed from a total beginner to a Launch Center Pro power user, my goal is to provide one for you here. Whether you’ve never even heard of Launch Center Pro until reading this, or you’re a seasoned veteran of the app, this article will familiarize you with the app’s full feature set.
iOS iOS App Launch Center Pro
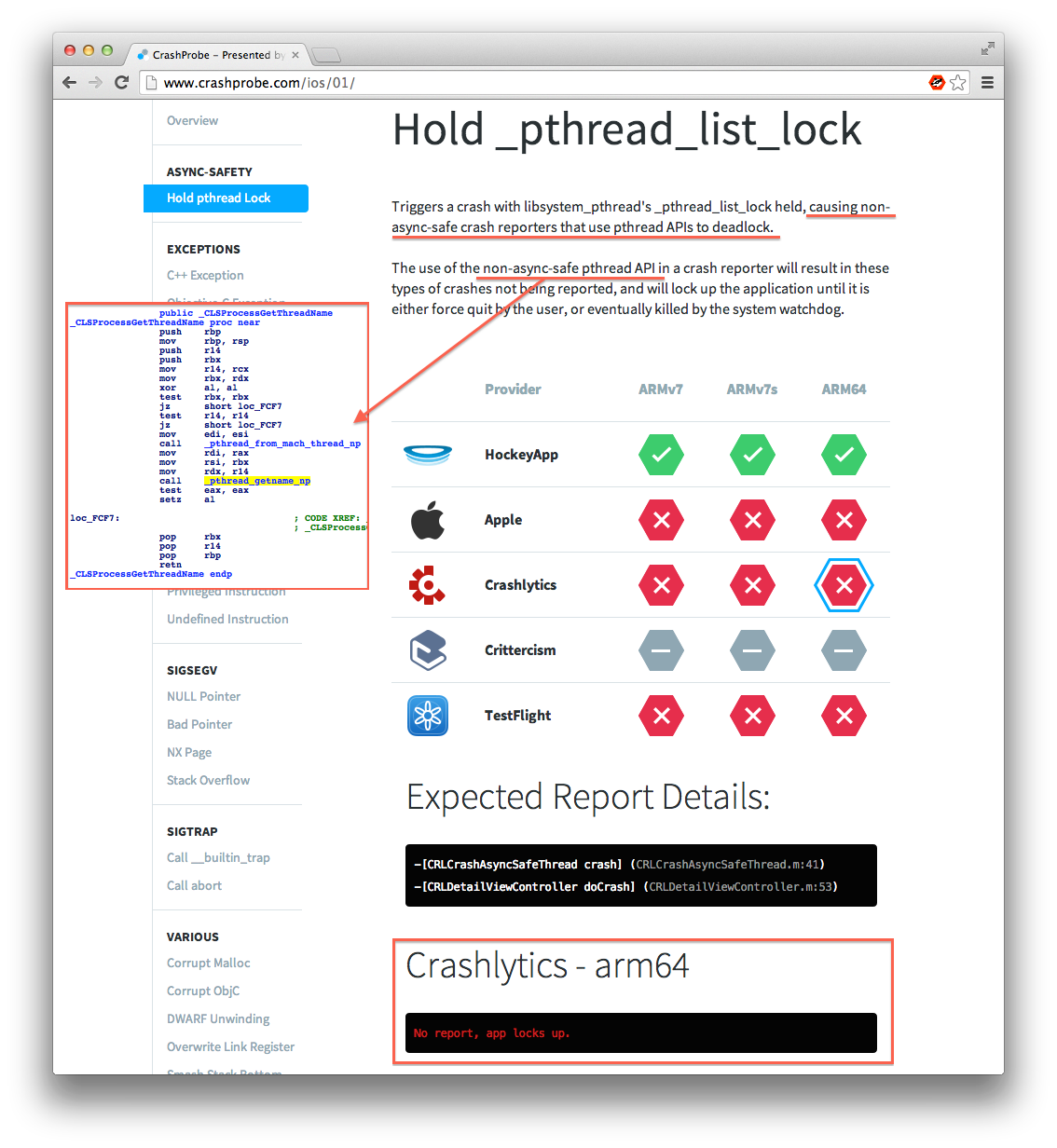{kind=link}
{kind=link}